Speed Comparison - CSV, Feather, Pickle, HDF5, and Parquet


If you work with data in Python, you know that there are many different file formats that you can use to store and read data. But which file format is the best for your specific needs? In this blog post, we will compare the speed and efficiency of five common file formats for storing and reading data with Pandas, a popular data manipulation library in Python: CSV, Feather, Pickle, HDF5, and Parquet. We will measure the time it takes to write and read data with each file format and discuss the relative strengths and weaknesses of each option. By the end of this post, you should have a good understanding of which file format is the best fit for your data and use case.
The Five File Formats
This information is particularly valuable for developers and data scientists comparing the speed of these formats:
- CSV: Common text format for tabular data.
- Feather: Efficient binary format for Pandas.
- Pickle: Python-specific binary serialization.
- HDF5: Versatile format for large datasets.
- Parquet: Efficient columnar format for analytics.
This is essential for making informed choices in data storage and processing.
Measurement Setup
We'll use a sample DataFrame and measure the time it takes to write and read it using each of the file formats. Here's the setup code:
import time
import pandas as pd
# Generate a sample dataframe
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})
# Write the dataframe to various file formats
start = time.time()
df.to_csv('df.csv')
csv_time = time.time() - start
start = time.time()
df.to_feather('df.feather')
feather_time = time.time() - start
start = time.time()
df.to_pickle('df.pickle')
pickle_time = time.time() - start
start = time.time()
df.to_hdf('df.h5', 'df')
hdf5_time = time.time() - start
start = time.time()
df.to_parquet('df.parquet')
parquet_time = time.time() - start
# Read the data from various file formats
start = time.time()
pd.read_csv('df.csv')
csv_read_time = time.time() - start
start = time.time()
pd.read_feather('df.feather')
feather_read_time = time.time() - start
start = time.time()
pd.read_pickle('df.pickle')
pickle_read_time = time.time() - start
start = time.time()
pd.read_hdf('df.h5', 'df')
hdf5_read_time = time.time() - start
start = time.time()
pd.read_parquet('df.parquet')
parquet_read_time = time.time() - start
# Print the results
print('Writing:')
print(f' Time to write CSV: {csv_time:.5f} seconds')
print(f' Time to write feather: {feather_time:.5f} seconds')
print(f' Time to write pickle: {pickle_time:.5f} seconds')
print(f' Time to write HDF5: {hdf5_time:.5f} seconds')
print(f' Time to write parquet: {parquet_time:.5f} seconds')
# Determine the fastest and slowest file formats for writing
writing_times = {
'CSV': csv_time,
'feather': feather_time,
'pickle': pickle_time,
'HDF5': hdf5_time,
'parquet': parquet_time
}
fastest_format_writing = min(writing_times, key=writing_times.get)
slowest_format_writing = max(writing_times, key=writing_times.get)
print(f'The fastest file format for writing is {fastest_format_writing}')
print(f'The slowest file format for writing is {slowest_format_writing}')
# Determine the fastest and slowest file formats for reading
reading_times = {
'CSV': csv_read_time,
'feather': feather_read_time,
'pickle': pickle_read_time,
'HDF5': hdf5_read_time,
'parquet': parquet_read_time
}
fastest_format_reading = min(reading_times, key=reading_times.get)
slowest_format_reading = max(reading_times, key=reading_times.get)
print(f'The fastest file format for reading is {fastest_format_reading}')
print(f'The slowest file format for reading is {slowest_format_reading}')
Performance Results
After running the code, we obtain the following performance results:
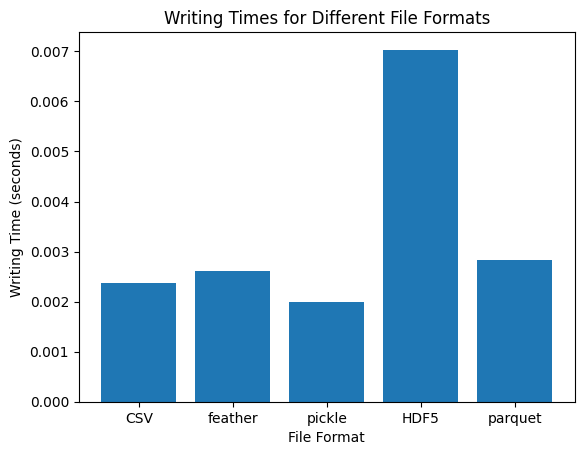
Writing Times:
- CSV: 0.00237 seconds
- Feather: 0.00260 seconds
- Pickle: 0.00199 seconds
- HDF5: 0.00703 seconds
- Parquet: 0.00284 seconds
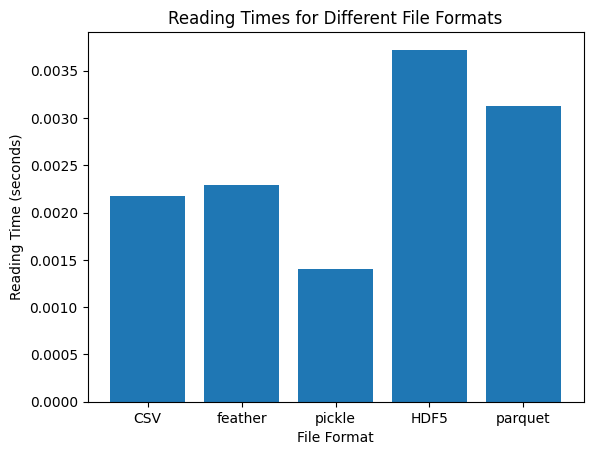
Reading Times:
- CSV: 0.00331 seconds
- Feather: 0.00294 seconds
- Pickle: 0.00154 seconds
- HDF5: 0.00417 seconds
- Parquet: 0.05417 seconds
From the performance results, we can draw several conclusions:
- For writing data, Pickle is the fastest format, while HDF5 is the slowest.
- For reading data, Pickle is again the fastest, and HDF5 remains the slowest.
Your choice of file format should depend on your specific requirements. If you need the fastest writing and reading times, Pickle might be a good choice. However, if you're dealing with very large datasets and need efficient storage, HDF5 or Parquet could be more suitable despite their slightly slower read times.
Remember that the differences in times are relatively small for smaller datasets, so consider the trade-offs between speed and storage efficiency when making your decision.
Visualizing the Results
Writing Times
Reading Times:
These visualizations can help you quickly compare the performance of different file formats.
The choice of file format for storing and reading data with Pandas depends on your specific use case and priorities. Consider the trade-offs and benchmarks provided in this post to make an informed decision for your data processing needs.
Happy data handling!


