DuckDB vs. Polars vs. Pandas - The Ultimate Performance Benchmark.


Today, I tried DuckDB and Polars, and both impressed me with their speed. However, I wanted to ensure that my insights weren’t biased by reading documentation alone. So, I focused on real-world use cases that I frequently encounter:
- GroupBy operations
- Filtering results
- Sorting results
- Loading large datasets
I initially skipped update operations(coz its not normally used for transactions but we can), but I think they should also be tested in the future...after all, updating records can be a critical feature in many applications.
To provide a fair comparison, I ran benchmarks on two different environments:
- Better-performance laptop (8-core CPU, 32GB RAM)
- Deepnote cloud instance (2 vCPU, 5GB RAM)
Why Use Parquet Instead of CSV?
I use Parquet for benchmarking instead of CSV because:
- Columnar Storage → Faster analytics, efficient compression.
- Compression → Reduces file size with formats like Snappy, Gzip, Zstd.
- Efficient Reads → Reads only the required columns instead of scanning entire rows.
- Parallelism → Works well with multi-threaded frameworks.
For our tests, I generated a 10-million-row dataset (193mb in size) and stored it as Parquet.
Benchmark Setup
Libraries Used
- Pandas: Most widely used, but single-threaded but no Pandas logo ツ.
- Polars: Built in Rust, optimized for multi-threading.
- DuckDB: A fast SQL-based database optimized for analytics.
Test Environment
- Laptop: Intel i7, 8 cores, 32GB RAM, NVMe SSD
- Deepnote Cloud: 2 vCPU, 5GB RAM (Lower computing power)
Dataset
- 10 million rows, 4 columns (id, category, value, timestamp)
- Stored in Parquet format.
Benchmark Results
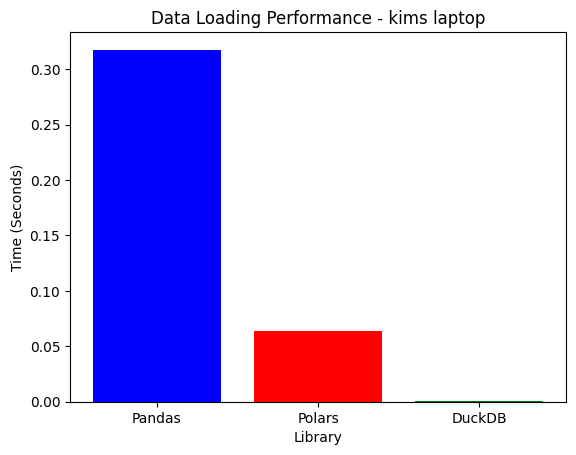
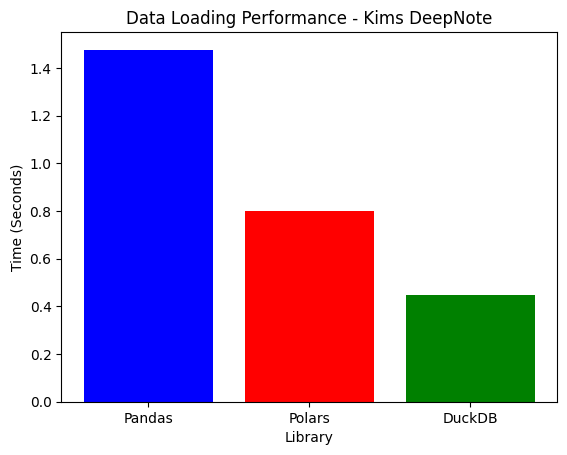
1. Data Loading Performance
| System | Pandas | Polars | DuckDB | Best |
|---|---|---|---|---|
| Laptop | 0.3339s | 0.0636s | 0.0098s | DuckDB |
| Deepnote | 1.4948s | 0.8069s | 0.4157s | DuckDB |
- DuckDB loads Parquet fastest, as it processes files directly without conversion overhead.
- Polars is 5x faster than Pandas due to its Rust-based columnar execution.
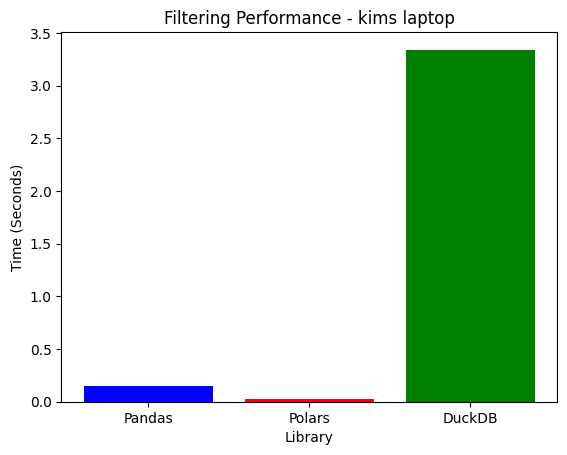
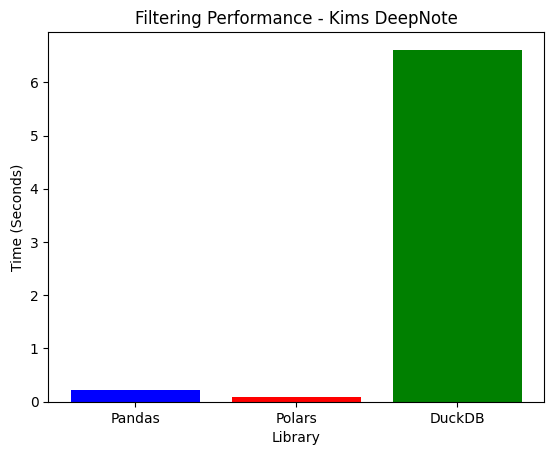
2. Filtering Performance
| System | Pandas | Polars | DuckDB | Best |
|---|---|---|---|---|
| Laptop | 0.3165s | 0.0269s | 3.4566s | Polars |
| Deepnote | 0.2215s | 0.1277s | 5.0982s | Polars |
- Polars is the fastest, leveraging SIMD acceleration & parallelization.
- DuckDB is extremely slow here as it scans the entire dataset before filtering.
3. GroupBy Aggregation Performance
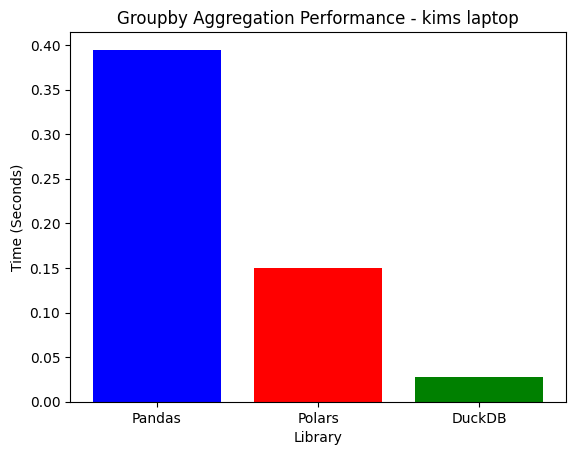
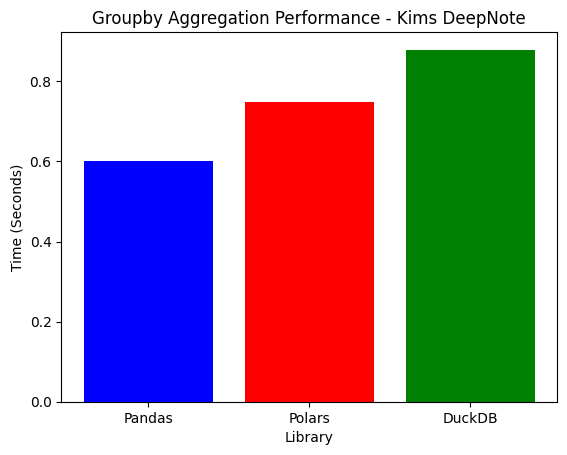
| System | Pandas | Polars | DuckDB | Best |
|---|---|---|---|---|
| Laptop | 0.5150s | 0.1574s | 0.0443s | DuckDB |
| Deepnote | 0.4969s | 0.6197s | 1.0923s | Pandas |
- On a high-core machine, DuckDB dominates groupby (11x faster than Pandas).
- On low-core Deepnote, Pandas surprisingly wins, as DuckDB's optimizations need more CPU cores.
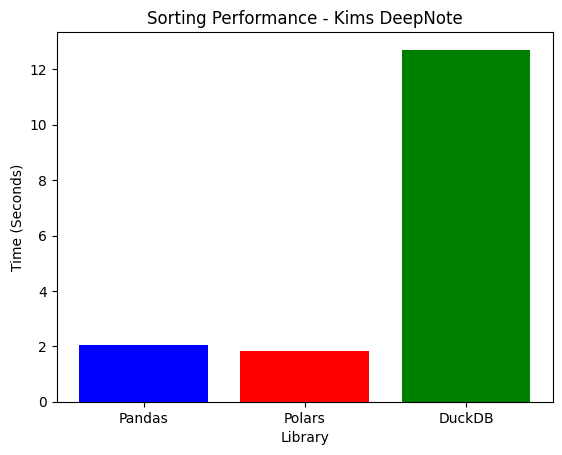
4. Sorting Performance
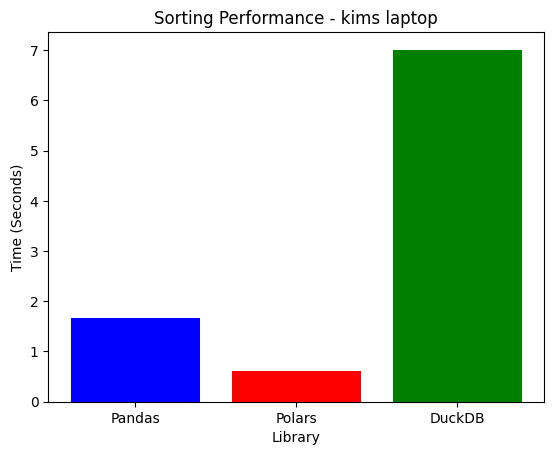
| System | Pandas | Polars | DuckDB | Best |
|---|---|---|---|---|
| Laptop | 1.9876s | 0.6471s | 8.1589s | Polars |
| Deepnote | 1.7048s | 1.5678s | 10.8224s | Polars |
- Polars is the best for sorting, scaling efficiently on both machines.
- DuckDB struggles heavily with sorting, taking 10x longer than Pandas.
Limitations of Each Framework
While each framework has strengths, they also come with limitations:
DuckDB
Writing to DuckDB from Multiple Processes
Writing to DuckDB from multiple processes is not supported automatically and is not a primary design goal (see Handling Concurrency).
- Single-writer limitation → Only one process can write at a time, making it unsuitable for high-concurrency updates. DuckDB's got trust issues...it only lets one process write at a time. I tried querying in my terminal and then in Python, but DuckDB was like, 'One at a time, buddy!' So yeah, no multitasking for me.
- Slow filtering → Compared to Polars, DuckDB is much slower at row-wise filtering.
- No real-time streaming support → Works best for batch analytics.
Polars
- Limited SQL support → While Polars is fast, it does not support full SQL operations like DuckDB.
- Write performance is still maturing → Writing data is not as optimized as reading.
- Higher memory usage for large datasets → Unlike DuckDB, which can spill to disk, Polars loads everything in RAM.
Pandas
- Slow for large datasets → Struggles with big data beyond memory size.
- Single-threaded execution → Unlike Polars and DuckDB, it does not use multiple CPU cores effectively.
- High memory usage → Row-oriented storage is less efficient than columnar approaches.
Key Insights
| Task | Best on Laptop (8-core) | Best on Deepnote (2-core) |
|---|---|---|
| Loading Data | DuckDB | DuckDB |
| Filtering | Polars | Polars |
| GroupBy | DuckDB | Pandas |
| Sorting | Polars | Polars |
Performance Takeaways:
- DuckDB is best for SQL-like analytics but needs multiple cores.
- Polars dominates filtering & sorting, making it the best for transformations.
- Pandas is still relevant in low-core environments.
Conclusion: Which Should You Use?
- If you need SQL-based analytics → Use DuckDB.
- If you need the fastest in-memory processing → Use Polars.
- If you're on limited hardware → Pandas may still be viable.
For a hands-on experience, check out the Deepnote Jupyter Notebook embed below to try it yourself!
Try It Yourself!
Here’s the full Jupyter Notebook on Deepnote to run benchmarks on your own system.