Failover and Replica


I’ve been thinking a lot about multi-region systems lately, especially around Keycloak-style setups.
And honestly, the more I worked with it, the more I realized something simple:
Failover and replication are usually treated like database problems, but they’re actually system design decisions.
The default standalone Keycloak setup in development mode can use H2, which runs as an embedded database inside the application process(its like no DB server). H2 is a single-node database engine and does not support replication or multi-region synchronization. While you can run multiple H2 instances independently, there is no built-in mechanism to replicate or keep them consistent across regions.
Let me explain it the way I eventually understood it myself...because it took me a while too when I first set up Keycloak and started working with it locally.
When you run Keycloak locally like this
docker run -p 127.0.0.1:8080:8080 -e KC_BOOTSTRAP_ADMIN_USERNAME=admin -e KC_BOOTSTRAP_ADMIN_PASSWORD=admin quay.io/keycloak/keycloak:26.6.1 start-devThe default behavior in start-dev: It typically uses an in-memory database(H2).
It’s fast for local development and can run either in in-memory mode or file-based mode, depending on how it’s configured. But in both cases, it runs inside the same process as Keycloak.
That’s important: it’s not a separate database service, it’s embedded.
And more importantly, it is not designed for production failover scenarios or multi-region setups.
And more importantly, it is not designed for production failover scenarios or multi-region setups.
That’s where the real gap shows up.
Because once you move out of local development, you’re no longer just thinking about “does it store data correctly”, but:
“what happens when part of the system disappears?”
With something like H2 Database, there’s no real concept of:
- replication between nodes
- failover between regions
- coordination between multiple writers
- or even a distributed boundary at all
It just runs inside the same application boundary.
So if the process stops, the “database” stops with it. There is nothing else that can take over, because there was never a separate system in the first place.
That’s why it works so well for local development, it removes all distributed complexity.
But it also means you can’t extend that model into a multi-region architecture. There is no mechanism to promote another instance, no shared log, no consensus layer, and no safe way to transfer “authority” to another region.
That’s exactly the point where systems like PostgreSQL start to matter, because now the database is no longer just part of the app—it becomes an independent system that can be replicated, observed, and reasoned about under failure.
And that shift is really where failover design begins.
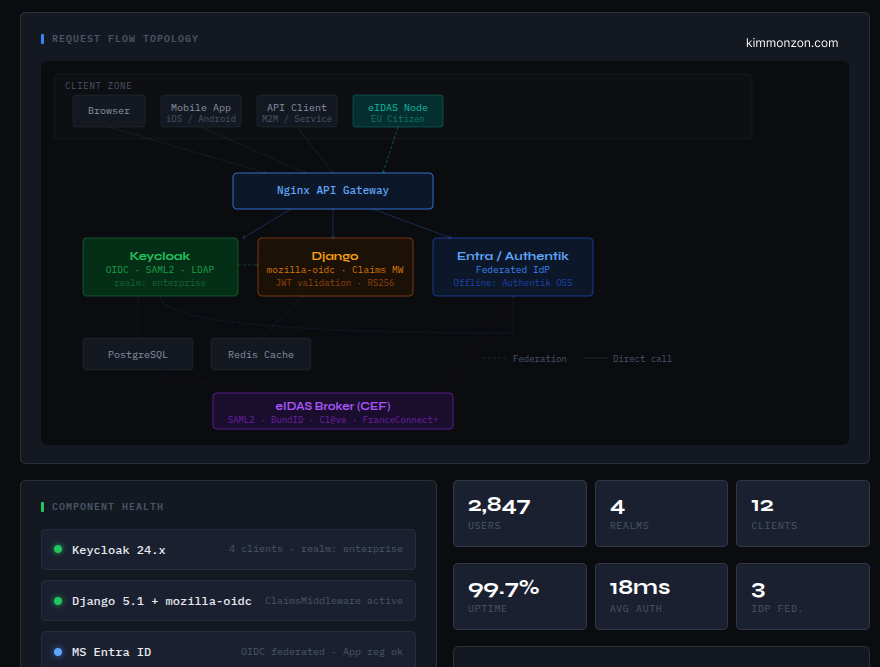
Why identity breaks differently in multi-region
For identity systems (Keycloak, OAuth/OIDC), “eventual consistency” is not just a database detail.
It becomes a security and correctness issue.
Because identity is full of state that changes meaning depending on time and authority:
- sessions and refresh tokens
- user creation / password changes
- role and group changes
- admin actions (disable user, rotate keys, revoke tokens)
So when people say “just run it in two regions”, the real question becomes:
“Which region is allowed to be the source of truth right now?”
If two regions can both accept writes, even for a short time, you get situations that are not easy to “merge” back safely.
Replication is not failover
Replication answers: “can Region B eventually get the data?”
Failover answers: “can Region B safely become the writer of truth now?”
Those are not the same thing.
If you promote a replica, you are not just “reading from another copy”.
You are transferring authority.
And if you transfer authority while the replica is behind, you’re accepting data loss (and sometimes security issues).
If you transfer authority while the old primary is still alive, you risk split-brain (two writers).
So in practice, you need a model that tells you when promotion is safe and when it is blocked.
Why H2 hides the real problem
H2 makes everything feel easy because it removes the distributed boundary completely.
No network, no replication, no replays, no promotion, no “who is primary”.
But the moment you switch to a real production model like PostgreSQL:
- there is an actual primary and standby role
- there is a log (WAL) that must be shipped and replayed
- there are delays, replays, and “caught up” vs “not caught up”
- promotion stops replication and regions can diverge
That’s what you want to see when you’re designing failover, because that’s the reality you’ll face.
Failover Criteria‑Based Architecture (the pattern)
The architecture pattern I used is basically:
- single-writer (active/passive)
- async streaming replication from primary → standby
- a decision layer that evaluates health + consistency + safety criteria
- a controller that only promotes/switches when criteria pass
- clear states so you can reason about what phase you’re in
The main idea is:
Failover is a decision, not a button.
The simulation architecture I built (local multi-region)
Even though this is “local”, I treated it like a real multi-region setup:
separate services, explicit routing, and explicit failover logic.
Components:
- Next.js UI (dashboard)
- FastAPI API layer (data plane API)
- Router service (LB simulation)
- Failover controller (control plane loop)
- PostgreSQL primary (Region A)
- PostgreSQL replica (Region B, streaming replication)
- Infra service (docker stats) — not in the critical path
Important architecture rules in this setup:
- replication is async (A → B)
- there is one writer
- infra/telemetry is background-only
How we set it up (Docker Compose)
Everything runs via docker compose.
Ports:
- UI:
http://localhost:3000 - Router:
http://localhost:8090 - API:
http://localhost:8080 - Infra:
http://localhost:7070/infra - Postgres region-a:
localhost:54321 - Postgres region-b:
localhost:54322
Bring it up:
chmod +x scripts/*.sh postgres/replica/bootstrap/*.sh postgres/primary/init/*.sh
./scripts/up.sh
Check current state:
./scripts/status.sh
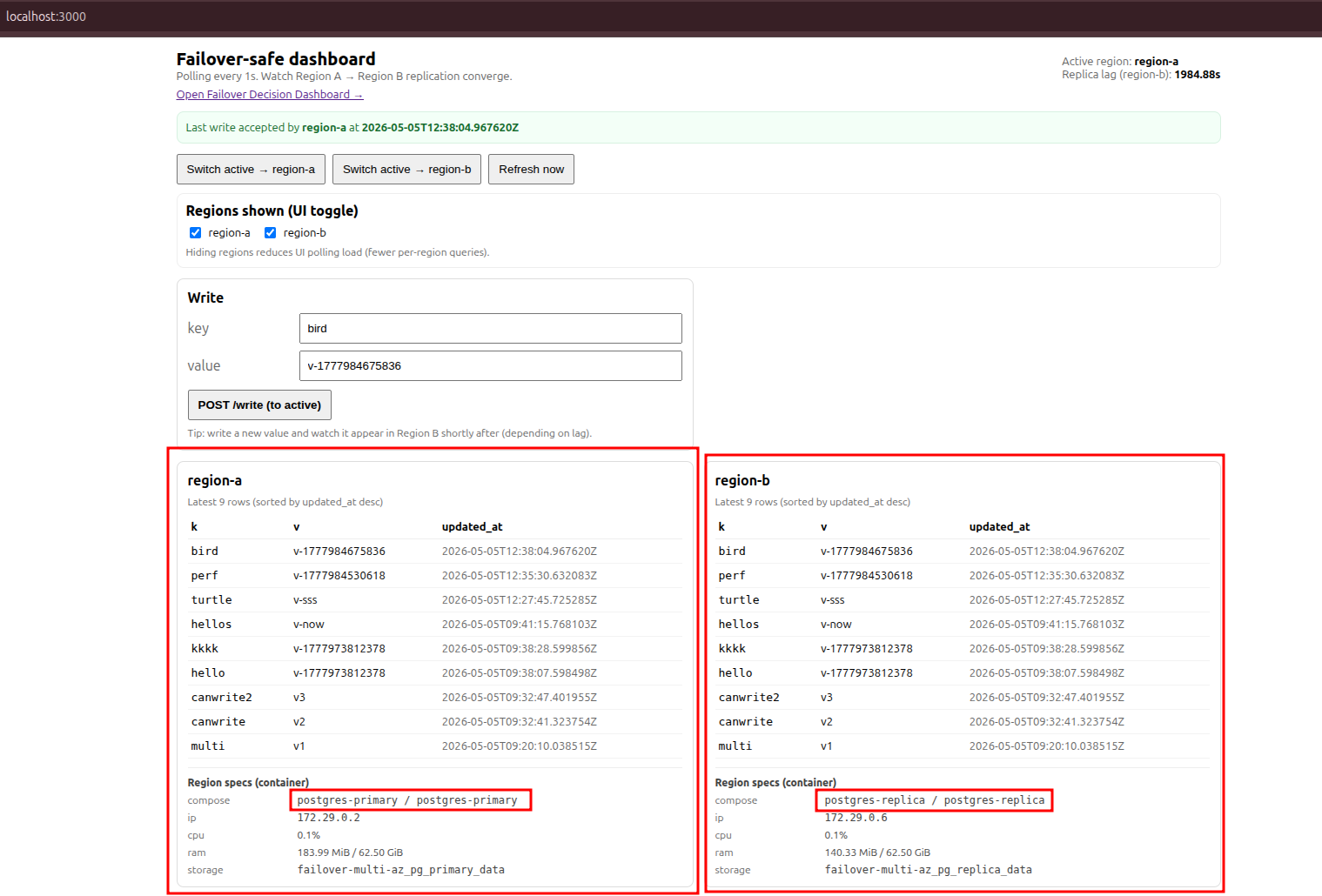
PostgreSQL replication model (what’s happening)
Region A starts as primary and Region B starts as a hot standby.
Region B is bootstrapped using:
pg_basebackup -R(clones the primary and writesprimary_conninfo)- a replication slot (so WAL is retained while the replica is connected)
While Region B is in recovery (pg_is_in_recovery()=true), it continuously replays WAL from Region A.
Important: replication is async.
So “I wrote it in A” does not guarantee “I can read it in B in the same millisecond”.
That’s expected.
API layer (data plane)
This is the service your UI and router call.
It’s responsible for:
- writing to the active region
- reading from the active region
- exposing status and decision data
- providing debug reads for each region (to visualize divergence / convergence)
Key endpoints:
POST /write(write key/value to active)GET /read?key=...(read from active)GET /status(health + roles + replication status)GET /decision(decision transparency: SAFE/BLOCKED + criteria)GET /dashboard(collapsed endpoint for UI: status + per-region latest rows)POST /admin/switch?region=region-a|region-b(switch active)GET /admin/kv?region=...&limit=...(list rows from a region)GET /admin/read?region=...&key=...(read a key from a specific region)
Example calls (through the router endpoint):
curl -sS "http://localhost:8090/status" | jq .
curl -sS "http://localhost:8090/decision" | jq .
curl -sS "http://localhost:8090/dashboard?limit=20" | jq .
Write:
curl -sS -X POST "http://localhost:8090/write" \
-H "content-type: application/json" \
-d '{"key":"hello","value":"world"}' | jq .
Read:
curl -sS "http://localhost:8090/read?key=hello" | jq .
Read from a specific region (to prove immediate commit vs replica replay delay):
curl -sS "http://localhost:8090/admin/read?region=region-a&key=hello" | jq .
curl -sS "http://localhost:8090/admin/read?region=region-b&key=hello" | jq .
Router (LB simulation)
The router is intentionally boring.
It gives you one stable endpoint and forwards requests to the API.
Why include it?
Because in real systems, clients rarely call the “primary DB region API” directly.
They call a stable hostname/load balancer and the routing changes behind the scenes.
Decision model: health, consistency, safety, stability
This is the most important part.
I added a failover decision endpoint (GET /decision) that returns:
- can we fail over right now?
- risk level (LOW/MEDIUM/HIGH)
- which checks passed/failed (so it’s explainable)
Checks:
- primary reachable?
- replica healthy?
- failure stable for N seconds? (avoid flapping)
- no split brain? (don’t automate when both can write)
- replication caught up? (receive LSN == replay LSN)
- WAL lag bytes below threshold? (prevent data loss)
This makes failover behavior transparent.
Instead of “it failed over randomly”, you can read the criteria output and see what’s blocking.
State machine: making failure modes explicit
To keep the system understandable, I treat it as a state machine:
- PRIMARY_ACTIVE
- STANDBY_READY
- PRIMARY_FAILED
- PROMOTING
- NEW_PRIMARY
- REJOINING
This matters because failover is not one action, it’s a transition.
And once you promote, you’ve changed the topology.
Control plane vs data plane
I separated responsibilities:
- data plane: UI → router → API → DB (fast path)
- control plane: controller evaluates
/decisionand triggers promotion + switch (slow and conservative)
This is exactly the same separation you see in real HA patterns.
It’s also what prevents “observability” from slowing down user traffic.
Infra stats are useful, but they must not be a dependency for writes/reads.
Why single-writer beats multi-write for identity
Active-active multi-write sounds attractive until you ask:
“How do I merge identity writes safely?”
Identity isn’t a shopping cart.
It’s security policy.
If two regions can both issue tokens, accept password changes, or mutate roles, you quickly end up needing:
- global ordering
- conflict resolution semantics that don’t break security
- and some kind of consensus/fencing anyway
So a single-writer + criteria-based failover model is the safer baseline.
What to measure and what to automate
If you want to automate failover, measure the things that decide safety:
- primary reachability duration (not just “one failed probe”)
- replica health
- WAL replay freshness (caught up)
- WAL lag bytes (data-loss risk)
- split-brain indicators
And automate only when criteria pass.
Otherwise, block and require an explicit operator action.
Conclusion: treat failover as a decision
The biggest lesson for me was:
Replication is not failover.
Failover is transferring authority.
And for identity systems, transferring authority without criteria is basically gambling with correctness and security.
So the right mental model is:
- define the decision criteria
- make it explainable
- make the state machine explicit
- separate control plane from data plane
That’s how a “database problem” turns into a system design that you can actually trust under failure.